Category Archives: SQL Server
SQL Server
Jak wymusić zwolnienie miejsca na dysku przez skasowane dane FILESTREAM
FILESTREAM jest mechanizmem silnika bazy danych SQL Server, który pozwala na przechowywanie danych binarnych bezpośrednio w systemie plików NTFS. O ile mechanizm ten jest już z nami trochę czasu (został wprowadzony w SQL Server 2008), to premiera SQL Server 2012 ukazała nam jego nową funkcjonalność, a mianowicie FILETABLE.
Więcej na temat FILESTREAM możemy przeczytać w tym miejscu.
Ci z was, którzy nie mieli jeszcze możliwości zapoznać się z FILETABLE mogą przeczytać artykuł mojego autorstwa znajdujący się na portalu wss.pl
Przyznam się, że przed ukazaniem się SQL Server 2012 nie byłem wielkim fanem mechanizmu FILESTREAM. Teraz natomiast – z uwagi na FILETABLE, który z niego korzysta – jak najbardziej TAK.
Używanie mechanizmu FILESTREAM jest obarczone pewnym problemem …
Dane przechowywane jako FILESTREAM są zapisywane bezpośrednio w systemie plików NTFS, a usuwane są za pomocą Garbage Collector-a. Oznacza to, że w przypadku usuwania danych niestety musimy trochę poczekać na odzyskanie miejsca na wolumenie.
Aby zobrazować tę sytuację stworzymy następujące środowisko testowe:
Na początek włączymy FILESTREAM dla instancji serwera. Aby tego dokonać należy użyć narzędzia SQL Server Configuration Manager znajdującego się w menu „Start Menu\Programs\Microsoft SQL Server 2012\Configuration Tools”:
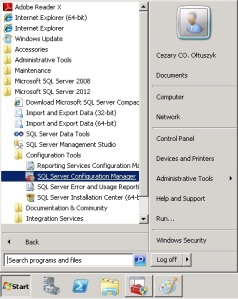
Po włączeniu Configuration Manager-a powinno się zaznaczyć wybraną usługę SQL Server, rozwinąć menu kontekstowe dostępne pod prawym przyciskiem myszki oraz wybrać opcję „Właściwości”. W tym momencie powinno pojawić się okno konfiguracyjne. Przechodzimy w nim do zakładki FILESTREAM i włączamy odpowiednie opcje:

Kolejnym krokiem jest przejście do SQL Server Mamagement studio i włączenie FILESTREAM wewnątrz usługi SQL:
EXEC sp_configure 'filestream access level', 2 GO RECONFIGURE GO
W tym momencie możemy utworzyć bazę testową bazę danych zawierającą katalog FILESTREAM:
CREATE DATABASE FileStreamDatabase ON PRIMARY ( NAME = 'FileStreamDatabase_prim', FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\FileStreamDatabase_prim.mdf', SIZE = 250, FILEGROWTH = 250 ), FILEGROUP FG_FILESTREAM CONTAINS FILESTREAM ( NAME = 'FileStreamDatabase_filestream', FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\FileStreamDatabase_filestream' ) LOG ON ( NAME = 'FileStreamDatabase_log', FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\FileStreamDatabase_log.ldf', SIZE = 250, FILEGROWTH = 250 )
Na koniec utworzymy tabelę przechowującą nasze dane binarne jako FILESTREAM:
CREATE TABLE dbo.tblFilestreamTest( id int PRIMARY KEY, rowID uniqueidentifier UNIQUE NOT NULL ROWGUIDCOL, data varbinary(max) FILESTREAM )
Czas na test !!!
Aby zobrazować problem wstawmy rekord do naszej tabeli:
INSERT dbo.tblFilestreamTest(id, rowID, data)
VALUES(1, NEWID(), CAST('aaaaa' AS varbinary(max)))
Następnie przejdźmy do katalogu przechowującego dane FILESTREAM i sprawdźmy jego zawartość:

Widzimy tutaj kilka katalogów. Ponieważ nie chciałbym się wdawać w dyskusję na temat w jaki sposób SQL Server dobiera nazwy, to musicie mi uwierzyć na słowo, że dane, które nas interesują znajdują się w folderze „2b131650-c3ba-43bd-94cf-80d17585c157„. Wewnątrz tego folderu będzie znajdować się kolejny katalog (w moim przypadku ma on nazwę „1baaed5d-ede2-4a24-b971-43bfae1f4b0f„), a w nim plik binarny z danymi:
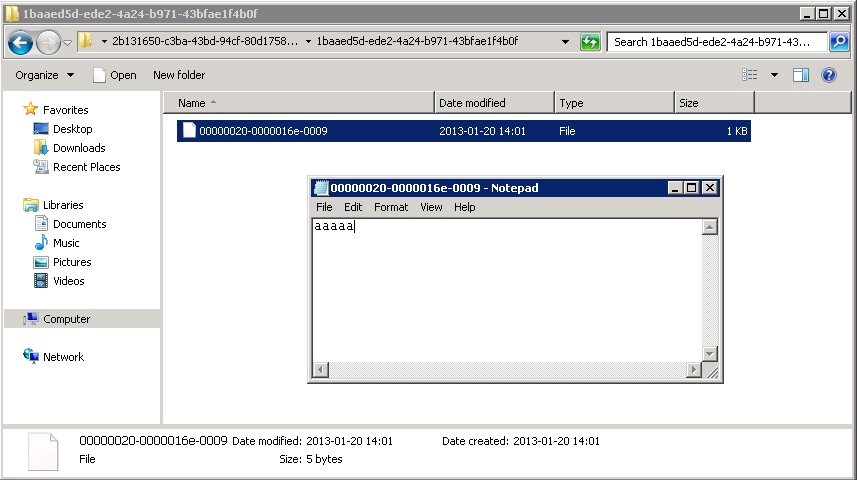
Na obrazku powyżej widać, że możemy spróbować otworzyć plik za pomocą notatnika i sprawdzić czy aby na pewno zawiera on nasze dane 🙂
Skoro już to zrobiliśmy, to teraz czas na DELETE … albo lepiej … zrobimy UPDATE …
UPDATE dbo.tblFilestreamTest
SET data = CAST('bbb' AS varbinary(max))
Mamy 2 pliki, jeden ze starymi wartościami, a drugi z nowymi !!! Co więcej, oba możemy otworzyć notatnikiem:

Stary plik będzie usunięty przez Garbage Collector, którego interwał działania nie jest określony. Przy odpowiednio dużym rozmiarze plików możemy bardzo szybko mieć problemy z wolnym miejscem na wolumenie z danymi.
Rozwiązanie
Do tej pory nie mieliśmy możliwości wymuszenia oczyszczenia dysku z niepotrzebnych wartości. SQL Server 2012 wprowadza nową procedurę systemową o nazwie sp_filestream_force_garbage_collection, która pozwala nam na uruchomienie Garbage Collector w wybranym przez nas momencie:
CHECKPOINT –- musimy to zrobić aby procedura zadziałała GO EXEC sp_filestream_force_garbage_collection @dbName = 'FileStreamDatabase', @filename = 'FileStreamDatabase_filestream'
Na obrazku poniżej widać efekt jej działania:

Dla niedowiarków przedstawiam jeszcze zrzut ekranu pokazujący, że w katalogu windowsowym mamy już tylko jeden plik:

Podsumowanie
Każda kolejna premiera SQL Server wiąże się ze zmianami w silniku baz danych. Zmiany te możemy podzielić na dwa rodzaje. Pierwsze, to te nagłaśniane przez Microsoft i zawarte niemalże w każdej broszurce reklamowej lub stronie www poświęconej temu produktowi. Drugie – „bardziej ciche” i niewystępujące w materiałach promujących. Są one często przydatne w szczególnych sytuacjach lub problemach z serwerem. Ja dzisiaj natknąłem się na procedurę sp_filestream_force_garbage_collection, która może okazać się niezbędna w sytuacji braku wolnego miejsca na dysku spowodowanego rozrostem danych przechowywanych jako FILESTREAM. Mam nadzieję, że i wy po przeczytaniu tego wpisu stwierdziliście, że procedura ta jest warta poświęcenia uwagi 🙂
Rzutowanie z typu money na varchar a utrata precyzji
Dzisiaj szybki w wpis o czymś, co mnie zaskoczyło podczas dzisiejszej pracy. Akurat traf chciał, że od jakiegoś czasu zajmuję się importem danych do SQL Server-a. Ciekawa sprawa na jaką trafiłem, to utrata precyzji podczas rzutowania typów money na varchar. O ile problemowe sytuacje podczas konwersji przytrafiają się, to akurat w „tę stronę” byłem zaskoczony…
Jak wyglądało moje rzutowanie?
Zacznijmy od przykładowego kodu, który będzie wyglądał w ten sposób:
DECLARE @m money = '13245.1234' SELECT @m AS PrzedRzutowaniem, CAST(@m AS varchar(50)) AS PoRzutowaniu

Na obrazku przedstawionym powyżej widać, że po rzutowaniu na varchar straciłem dwie ostatnie cyfry. Nie przypuszczałem, że zwykły CAST na typ znakowy jest w stanie to zrobić. Rozumiem, gdy utrata precyzji ma miejsce w przypadku CAST z varchar na money … Tu jednak rzutowałem odwrotnie w celu dalszego wyświetlenia wartości.
Rozwiązanie
Jak to zwykle bywa, niezbędne stało się użycie funkcji CONVERT i specjalnie do tego celu stworzonego parametru:
DECLARE @m money = '13245.1234' SELECT @m AS PrzedRzutowaniem, CONVERT(varchar(50), @m, 2) AS PoRzutowaniu

Użycie „2” w CONVERT-cie daje oczekiwany efekt. Powyższy zrzut ekranu pokazuje, że tym razem jest już OK 🙂
Podsumowanie
Na problemy konwersji każdy z nas natknął się pewnie wiele razy. Standardem jest poświęcenie uwagi podczas rzutowań z typów znakowych na inne. Jak widać w sytuacji odwrotnej też trzeba mieć się na baczności.
Plany zapytań w cache-u a zmiana MAXDOP na poziomie serwera
SQL Server obsługując zapytania użytkowników potrafi sam zadecydować z ilu rdzeni ma w danym momencie skorzystać. Do kontroli maksymalnej ilości wątków służy nam opcja o nazwie nazwie „max degree of parallelism„.
Celem wpisu nie jest jednak wyjaśnienie wam jak ta opcja działa, lecz pokazanie jaki jest poboczny skutek jej przestawienia 🙂
Co nas może nas zaskoczyć?
Na początek zalogujmy się do naszego serwera i sprawdźmy planów zapytań znajduje się w naszym CECHE-u:
SELECT COUNT(*) AS ilePlanow FROM sys.dm_exec_cached_plans

Na obrazku powyżej widać, że jest ich 49. Zmieńmy w takim razie konfigurację:
EXEC sp_configure 'show advanced options', 1 RECONFIGURE EXEC sp_configure 'max degree of parallelism', 4 RECONFIGURE
I odpytajmy się ponownie o ilość planów w CACHE-u:
SELECT COUNT(*) AS ilePlanow FROM sys.dm_exec_cached_plans

Tym razem planów jest dwanaście 🙂
Czyżby SQL Server wyczyścił CACHE?
Wygląda na to, że TAK. Czy jednak jesteśmy w stanie udowodnić ten fakt w niedający złudzeń sposób … poniżej przedstawiam wycinek logu, który może nas zainteresować:

Informacja tam zawarta jest dość jasna:
SQL Server has encountered 1 occurrence(s) of cachestore flush for the ‚Object Plans’ cachestore (part of plan cache) due to some database maintenance or reconfigure operations.
Możemy być pewni, że to zmiana MAXDOP na poziomie serwera wyczyściła nam zbuforowane plany zapytań, co może nieść negatywny skutek wydajnościowy przez kilka kolejnych minut działania serwera.
Podsumowanie
Wszelkie zmiany ustawień produkcyjnych serwerów SQL powinny być przez nas przemyślane. O ile opcja ‚max degree of parallelism’ jest powszechnie znana, to skutek poboczny jej przestawienia – już nie koniecznie. Zanim zaczniemy ją zmieniać, przemyślmy czy może zrobić to w czasie, gdy nasz procesor nie jest zbyt obciążony pracą i wygenerowanie nowych planów nie będzie wpływać na pracę użytkowników końcowych.
Drobna (stara) zmiana w komunikacie błędu, o której właśnie się dowiedziałem :)
Wakacje się już skończyły, tak więc i ja powoli wracam do blogowania. Dzisiejszym wpisem chciałbym pokazać dość drobną zmianę, którą właśnie odkryłem testując SQL Server 2012. Co więcej zmiana ta została wprowadzona we wcześniejszych wersjach SQL Server-a, a ja najzwyczajniej ją przeoczyłem 🙂
Na początek przygotowanie sytuacji problemowej
Wyobraźmy sobie sytuację w której mamy zdefiniowaną tabelę do której importujemy dane z zewnętrznego źródła. Przykładowa struktura takiej tabeli mogłaby wyglądać następująco:
CREATE TABLE #t ( id int PRIMARY KEY, KolumnaA varchar(100) )
Wypełnijmy ją kilkoma przykładowymi rekordami:
INSERT INTO #t(id, KolumnaA) SELECT 1, 'aaa' UNION ALL SELECT 2, 'bbb' UNION ALL SELECT 3, 'ccc'
A teraz zasymulujmy problem
Do tego celu posłużymy się instrukcją INSERT podobną do tej, która wypełnialiśmy przykładową tabelę:
INSERT INTO #t(id, KolumnaA) SELECT 11, '111111' UNION ALL SELECT 2, '22222' UNION ALL SELECT 33, '33333'
Druga wartość wstawiana do tabeli spowoduje wygenerowanie błędu (duplikat w kluczu głównym tabeli). Do tej pory wszelkiego rodzaju importy robiłem na SQL Server 2005 i komunikat błędu wyglądał tak:
Msg 2627, Level 14, State 1, Line 1Violation of PRIMARY KEY constraint ‚PK__#t________________4D8FEC29’. Cannot insert duplicate key in object ‚dbo.#t’.
The statement has been terminated.
Podczas testów SQL Server 2012 zaskoczyła mnie nieco zmieniona treść komunikatu:
Msg 2627, Level 14, State 1, Line 1Violation of PRIMARY KEY constraint ‚PK__#t________3213E83F4AD2AC5D’. Cannot insert duplicate key in object ‚dbo.#t’. The duplicate key value is (2).
The statement has been terminated.
Jakby nie patrzeć jest o wiele przyjemniej. Od razu widać jaka wartość powoduje problem z wpisaniem wartości do tabeli.
Czy to jest zmiana wprowadzona w SQL Server 2012 ??
Pracując z różnymi wersjami SQL Server-ów człowiek zaczyna się zastanawiać, czy to co właśnie odkrył jest faktycznie nowością, czy może jest to nowość tylko i wyłącznie dla niego. W badanym przypadku okazało się, że jest to nowość, która istniała na 100% w SQL Server 2008R2. Niestety nie miałem możliwości sprawdzenia czy SQL 2008 też obsługuje badany błąd w ten sam sposób, tak więc jeżeli ktoś z was ma tę wersję pod ręką – chętnie się dowiem 🙂
Podsumowanie
Platforma SQL Server jest na tyle spora, że nawet kilka lat po wprowadzeniu danej wersji można odkryć w niej coś nowego. W moim przypadku testując najnowszą wersję odkryłem coś, co zostało wprowadzone kilka lat temu 🙂
Mity o SQL Server: Ilość rdzeni na serwerze a ilość plików tempdb
Na początku maja rozpocząłem serię postów, mówiącą na temat różnego rodzaju mitów i niedomówień związanych z działaniem SQL Server. Zgodnie z obietnicą tematem drugiego wpisu będzie następujący mit:
„Ilość plików w tempdb powinna być równa ilości rdzeni na jakich pracuje SQL”Mit ten jest dość popularny i jak zauważył mmoskit można na ten temat znaleźć oficjalne wzmianki w white paper-ach wydanych przez Microsoft, np:
http://www.microsoft.com/en-us/download/details.aspx?id=18473
„Make as many tempdb files as you have physical CPU, accounting for any affinity mask settings. Do not factor in hyperthreading or dual cored CPUs into the count ”W dalszej części tego wpisu chciałbym pokazać, dlaczego nie warto stosować się do tego zalecenia „z automatu”., gdyż może ono prowadzić do utraty wydajności zainstalowanej instancji.
Środowisko testowe:
Zanim zaczniemy test, przedstawię nieco środowisko testowe. Konfiguracja sprzętowa wygląda następująco:
- SERWER HP DL 360 GS
- 2 x Intel Xeon E5420 Quad Core 2,5 GHz
- 8 GB RAM
- 2 x HDD 146 GB, 10000rpm – zestawione w RAID 1
- 2 x HDD 74GB 15000rpm – widoczne pojedynczo (oddzielnie)
Jeśli chodzi o zainstalowane oprogramowanie, to posłużyłem się:
- WINDOWS 2008R2 SP1 w Enterprise
- SQL Server 2012 Enterprise
- Przykładową bazą danych ContosoRetailDW
Całość została ustawiona przeze mnie w następujący sposób:
- System wraz z silnikiem SQL i bazami (za wyjątkiem tempdb) na dyskach 146GB 10000 obr/min
- Pliki danych tempdb na dysku 74 GB 15000 obr/min (zamontowanym jako dysk logiczny F)
- Plik logu tempdb na dysku 74 GB 15000 obr/min (zamontowanym jako dysk logiczny G)
- Affinity Mask Serwera SQL ustawiona na zero (używam wszystkich rdzeni)
- Min Server Memory = 1000MB, Max Server Memory = 6000 MB
Ustawienie zgodnie z zaleceniem MS
Wykonany test zacząłem od ustawienia instancji zgodnie z przytoczonym white paper-em. Ponieważ mój serwer jest ośmiordzeniowy, to baza tempdb powinna mieć 8 plików danych o takiej samej zaalokowanej ilości miejsca na dysku:

Następnie stworzyłem proste zapytanie, które będzie obciążać bazę tempdb:
SELECT * INTO #t FROM ContosoRetailDW.dbo.[FactITMachine] DROP TABLE #t
Test właściwy polegał na odpaleniu powyższego skryptu w 10 wątkach po 100 razy za pomocą programu SQLQueryStress. Wynik tej operacji – nieco ponad minuta (próba była powtarzana 3 razy, do zestawienia brany był najniższy wynik):

Ustawienie niezgodne z zaleceniem MS
Drugą częścią testu było ustawienie bazy tempdb w taki sposób, aby miała tylko jeden plik danych:

Następnie odpaliłem stworzony wcześniej skrypt. Ponownie w 10 wątkach po 100 razy. Czas wykonania był tym razem około 30% krótszy, gdyż wynosił 45 sekund:

Dlaczego ustawienie zgodne z zaleceniem jest GORSZE ?!!!
Przyczyną zmniejszonej wydajności operacji I/O w bazie tempdb jest „fizyczność” dysku twardego, na którym posadowiłem pliki z danymi. Konfigurując bazę tempdb na oddzielnym dysku i tworząc w niej 8 równych plików z danymi sprawiliśmy, że SQL Server zaczął używać mechanizmu proporcjonalnego wypełnienia. Sprawdźmy w jaki sposób ten algorytm zadziałał w badanym przypadku:
1. Ustawmy baze tempdb tak, aby miała 8 plików z danymi
2. Odpalmy pierwszą część skryptu używając SQL Server Management Studio:
SELECT * INTO #t FROM ContosoRetailDW.dbo.FactITMachine
3. Sprawdzamy w jakich plikach są przechowywane dane naszej tabeli:
SELECT REPLACE(LEFT(sys.fn_PhysLocFormatter(%%physloc%%), 2), '(', '') AS FileID,
COUNT(*) As NumRows
FROM #t
GROUP BY LEFT(sys.fn_PhysLocFormatter(%%physloc%%), 2)
ORDER BY FileID

Jak widać na powyższym zrzucie ekranu, SQL Server porozdzielał wiersze pomiędzy pliki. Algorytm proporcjonalnego wypełnienia sprawił, że głowica dysku twardego musiała zmieniać pozycję „skacząc” pomiędzy plikami sprawiając, że zapis na nich był wolniejszy.
Poniżej przedstawiam zrzuty ekranów z Resource Monitora, najpierw dla konfiguracji z 8 plikami:

A teraz dla jednego pliku z danymi:

Porównując oba obrazki widać, że różnica w szybkości zapisu jest znaczna (35MB vs 59MB na korzyść konfiguracji z 1 plikiem)
Podsumowanie
Stosowanie się do przytoczonego zalecenia MS odnośnie konfiguracji bazy tempdb może powodować spadek wydajności SQL Server. W erze wielordzeniowych procesorów, gdzie serwery bazodanowe mogą bez większego problemu posiadać po kilkadziesiąt rdzeni, utworzenie takiej samej ilości plików z danymi tempdb może okazać się dosyć kiepskim pomysłem. W związku z powyższym jestem zwolennikiem niestosowania się do tego zalecenia z automatu. Należy jednak w tym miejscu wspomnieć, że istnieją sytuacje w których zwiększenie ilość plików poprawia osiągi serwera. Jedną z takich sytuacji jest np. problem z dostępem do stron PFS w tempdb – co możliwe, że będzie tematem do dalszych rozważań i kolejnych wpisów 🙂
Edit: Dla niedowiarków 🙂
Aby nie być gołosłownym, sprawdziłem jak będzie wyglądać odczyt z takiej tabeli w zależności od ilości plików tempdb. Test jest dosyć prosty i wyglądał następująco:
1. Ponowna konfiguracja tempdb, tak aby miała 8 plików z danymi
2. Utworzenie tabeli testowej:
SELECT * INTO tempdb.dbo.test FROM ContosoRetailDW.dbo.FactITMachine
3. Cykliczne wykonanie następującego wsadu T-SQL:
-- Czyścimy RAM serwera CHECKPOINT DBCC DROPCLEANBUFFERS -- odpalamy zapytanie (dane z dysku) SELECT COUNT(*) FROM tempdb.dbo.test OPTION (QUERYTRACEON 8649)
Wynik tego zabiegu można zobaczyć poniżej (ponad 9 sekund):

Analogiczny test przeprowadzony dla tempdb z jednym plikiem (nieco ponad 7 sekund):

Podsumowanie dla niedowiarków 🙂
Niezależnie czy piszemy, czy odczytujemy dane z bazy tempdb ustawionej zgodnie z zaleceniem MS, to wydajność serwera jest niższa niż w przypadku posiadania tylko 1 pliku tempdb przy badanej konfiguracji dyskowej.

